Веб-парсинг для начинающих с Python и Repl.it¶
В этом руководстве мы рассмотрим, как автоматически получать данные с веб-сайтов. Большинство веб-сайтов создаются с расчетом на человеческую аудиторию - вы используете поисковую систему или вводите URL-адрес в свой веб-браузер и видите информацию, отображаемую на странице. Иногда нам может потребоваться автоматическое извлечение и обработка этих данных, и именно в этом случае очистка веб-страниц может спасти нас от утомительной повторяющейся работы. Мы можем создать специальную компьютерную программу для посещения веб-сайтов, извлечения определенных данных и обработки этих данных определенным образом.
Мы будем извлекать данные новостей с новостного веб-сайта bbc.com , но вы сможете адаптировать его для извлечения информации с любого веб-сайта, который вам нужен, методом проб и ошибок.
Есть много причин, по которым вы можете захотеть использовать парсинг веб-страниц. Например, вам может потребоваться:
- извлекать цифры из отчета, который выпускается еженедельно и публикуется в Интернете
- возьмите расписание любимой спортивной команды по мере его выхода
- найти даты выхода предстоящих фильмов в любимом жанре
- получать автоматические уведомления при изменении веб-сайта
Есть много других вариантов использования веб-скрапинга. Однако следует также отметить, что законы об авторском праве и законы об очистке веб-страниц сложны и различаются в зависимости от страны. Если вы явно не копируете их контент или не выполняете парсинг в коммерческих целях, люди, как правило, не возражают против этого. Однако было несколько судебных дел, связанных со сбором данных из LinkedIn и вниманием СМИ из-за сбора данных из OKCupid . Очистка веб-страниц может нарушать закон, противоречить условиям обслуживания определенного веб-сайта или нарушать этические принципы, поэтому будьте осторожны с тем, где вы применяете этот навык.
Убрав заявление об отказе от ответственности, давайте научимся соскабливать его!
Обзор и требования¶
В частности, в этом уроке мы рассмотрим:
- Что такое веб-сайт на самом деле и как работает HTML
- Просмотр HTML в вашем веб-браузере
- Использование Python для загрузки веб-страниц
- Использование BeautifulSoup для извлечения частей очищенных данных
Мы будем использовать онлайн-среду программирования Repl.it, поэтому вам не нужно будет устанавливать какое-либо программное обеспечение локально, чтобы выполнять пошаговые инструкции . Если вы хотите адаптировать это руководство к своим потребностям, вам следует создать бесплатную учетную запись, перейдя на repl.it и проследив за их процессом регистрации.
Было бы полезно, если у вас есть базовые знания Python или другого языка программирования высокого уровня, но мы будем подробно объяснять каждую строку кода, который мы пишем, чтобы вы могли не отставать или, по крайней мере, воспроизвести результат, даже если ты этого не сделаешь.
Веб-страницы: красавица и чудовище¶
Вы, несомненно, раньше посещали веб-страницы с помощью веб-браузера. Веб-сайты существуют в двух формах:
- Тот, к которому вы привыкли, где вы можете видеть текст, изображения и другие медиафайлы. Для удобного и (обычно) эстетичного отображения информации используются разные шрифты, размеры и цвета.
- «Источник» веб-страницы. Это компьютерный код, который сообщает вашему веб-браузеру (например, Mozilla Firefox или Google Chrome), что и как отображать.
Веб-сайты создаются с помощью комбинации трех компьютерных языков: HTML, CSS и JavaScript. Само по себе это огромная и сложная область с запутанной историей, но для эффективной автоматизации парсинга веб-страниц необходимо иметь общее представление о том, как некоторые из них работают. Если вы откроете какой-либо веб-сайт в своем браузере и щелкните правой кнопкой мыши где-нибудь на странице, вы увидите меню, которое должно включать параметр «просмотреть исходный код страницы» - для проверки формы кода веб-сайта, прежде чем ваш веб-браузер интерпретирует его. .
Это показано на изображении ниже: обычная веб-страница слева с открытым меню (отображается при щелчке правой кнопкой мыши на странице). Нажав «просмотреть исходный код страницы» в этом меню, вы увидите результат справа - мы можем увидеть код, содержащий все данные и вспомогательную информацию, которые необходимы веб-браузеру для отображения полной страницы. В то время как страницу слева легко читать, использовать и она хорошо выглядит, страница справа выглядит чудовищно. Чтобы разобраться в этом, требуются некоторые усилия и опыт, но это возможно и необходимо, если мы хотим писать собственные парсеры.

Изображение 1: Обычный и исходный вид одной и той же новостной статьи BBC.
Навигация по исходному коду с помощью поиска¶
Первое, что нужно сделать, - это выяснить, как соотносятся две страницы: какие части обычно отображаемого веб-сайта соответствуют каким частям кода. Вы можете использовать «найти» Ctrl + F) в представлении исходного кода, чтобы найти определенные фрагменты текста, которые видны в обычном представлении, чтобы помочь в этом. На веб-странице слева мы видим, что история начинается с фразы «Получение работы на телевидении». Если мы ищем эту фразу в представлении кода, мы можем найти соответствующий текст в коде в строке 805.

Изображение 2: Поиск текста в исходном коде веб-страницы.
<p class="story-body__introduction">Непосредственно перед подсвеченной разделе HTML - код , чтобы указать , что пункт ( <p>в HTML) начинается здесь , и что это особый вид пункта (введение в историю). Абзац продолжается до </p>символа. Вам не нужно беспокоиться о полном понимании HTML, но вы должны знать, что он содержит как текстовые данные, из которых состоит новость, так и дополнительные данные о том, как их отображать.
Большая часть веб-скрапинга просматривает такие страницы, чтобы: а) идентифицировать интересующие нас данные и б) отделить их от разметки и другого кода, с которым они смешаны. Даже до того, как мы начнем писать наш собственный код, все еще может быть сложно сначала понять других людей.
На большинстве страниц есть много кода для определения структуры, макета, интерактивности и других функций веб-страницы, и относительно немного кода, который содержит фактический текст и изображения, которые мы обычно просматриваем. Для особенно сложных страниц может быть довольно сложно, даже с помощью функции поиска, найти код, который отвечает за определенную часть страницы. По этой причине большинство веб-браузеров поставляются с так называемыми «инструментами разработчика», которые в первую очередь нацелены на программистов и помогают в создании и обслуживании веб-сайтов, хотя эти инструменты также удобны для выполнения парсинга веб-страниц.
Навигация по исходному коду с помощью инструментов разработчика¶
Вы можете открыть инструменты разработчика для своего браузера из главного меню, при этом Google Chrome показан слева, а Mozilla Firefox - справа внизу. Если вы используете другой веб-браузер, вы сможете найти аналогичный параметр.

** Изображение 3: ** Открытие инструментов разработчика в Chrome (слева) и Firefox (справа)
Активация инструмента вызывает появление новой панели в вашем веб-браузере, обычно внизу или справа. Инструмент содержит панель «Инспектор» и инструмент выбора, который можно выбрать, нажав значок, выделенный красным ниже. Когда инструмент выбора активен, вы можете щелкать по частям веб-страницы, чтобы просмотреть соответствующий исходный код. На изображении ниже мы выбрали тот же первый абзац в обычном представлении, и мы <p class=story-body__introduction">снова можем увидеть код на панели ниже.

Изображение 4. Просмотр кода определенного элемента с помощью инструментов разработчика.
Инструменты разработчика значительно более мощные, чем использование простого инструмента поиска, но они также более сложные. Вам следует выбрать метод, основанный на вашем опыте и сложности страницы, которую вы пытаетесь проанализировать.
Загрузка веб-страницы с помощью Python¶
Теперь, когда мы узнали немного больше о том, как веб-страницы создаются в нашем браузере, мы можем начать извлекать их и управлять ими с помощью Python. Поскольку Python не является веб-браузером, мы сможем только извлекать исходный код HTML и управлять им, а не просматривать «нормальное» представление веб-страницы.
Мы сделаем это через Python Repl, используя requestsбиблиотеку. Откройте repl.it и выберите создание нового Python Repl.

Изображение 5: Создать новый Repl
Это перенесет вас в рабочую среду кодирования Python, где вы сможете писать и запускать код Python. Для начала мы загрузим контент с домашней страницы BBC News и распечатаем первые 1000 символов исходного кода HTML.
Вы можете сделать это с помощью следующих четырех строк Python:
import requests
url = "https://bbc.com/news"
response = requests.get(url)
print(response.text[:1000])
Поместите этот код в main.pyфайл, который Repl автоматически создает для вас, и нажмите кнопку «Выполнить». После небольшой задержки вы должны увидеть результат на панели вывода - начало исходного кода HTML, аналогично тому, что мы просматривали в нашем веб-браузере выше.

Изображение 6: Загрузка отдельной страницы с помощью Python
Давайте разделим каждую из этих линий.
- В строке 1 мы импортируем
requestsбиблиотеку Python , которая позволяет нам делать веб-запросы. - В строке 3 мы определяем переменную, содержащую URL-адрес основного новостного сайта BBC. Вы можете посетить этот URL-адрес в своем веб-браузере, чтобы увидеть домашнюю страницу BBC News.
- В строке 4 мы передаем URL-адрес, который мы определили,
requests.getфункции, которая посетит веб-страницу, на которую указывает URL-адрес, и получит исходный HTML-код. Мы загружаем это в новую переменную с именемresponse. - В строке 5 мы получаем доступ к
textатрибуту нашегоresponseобъекта, который содержит весь исходный код HTML. Мы берем только первые 1000 символов этого и передаем ихprintфункции, которая просто выгружает получившийся текст в нашу панель вывода.
Теперь мы автоматически получили веб-страницу и можем отображать части содержимого. Нам вряд ли будет интересен полный дамп исходного кода веб-страницы (если мы не сохраняем его для архивных целей), поэтому давайте извлечем некоторые интересные части страницы, а не только первые 1000 символов.
Использование BeautifulSoup для извлечения всех URL-адресов¶
Всемирная паутина состоит из страниц, которые ссылаются друг на друга с помощью гиперссылок, ссылок или URL-адресов. (Эти термины используются более или менее взаимозаменяемо).
Предположим, что мы хотим найти все новостные статьи на главной странице BBC News и получить их URL-адреса. Если мы посмотрим на главную страницу ниже, мы увидим, что на главной странице есть куча историй. Наведя курсор мыши на любой из заголовков с помощью инструмента «проверить», мы можем увидеть, что у каждого из них есть уникальный URL-адрес, который ведет нас к этой новости. Например, если навести курсор мыши на основную историю «США и Канада договорились о новой торговой сделке» на изображении ниже, это ссылка на https://www.bbc.com/news/business-45702609.
Если мы проверим этот элемент с помощью инструментов разработчика браузера, мы увидим, что это <a>элемент, который представляет собой HTML для ссылки, с <href>компонентом, указывающим на URL. Обратите внимание, что hrefраздел идет только до последней части URL-адреса, опуская часть https://www.bbc.com. Поскольку мы уже работаем на BBC, сайт может использовать относительные URL-адреса вместо абсолютных . Это означает, что когда вы нажимаете на ссылку, ваш браузер определит, что URL-адрес неполный, и добавит к нему https://www.bbc.com. Если вы посмотрите исходный код главной страницы BBC, вы найдете как относительные, так и абсолютные URL-адреса, что уже затрудняет очистку всех URL-адресов на странице.
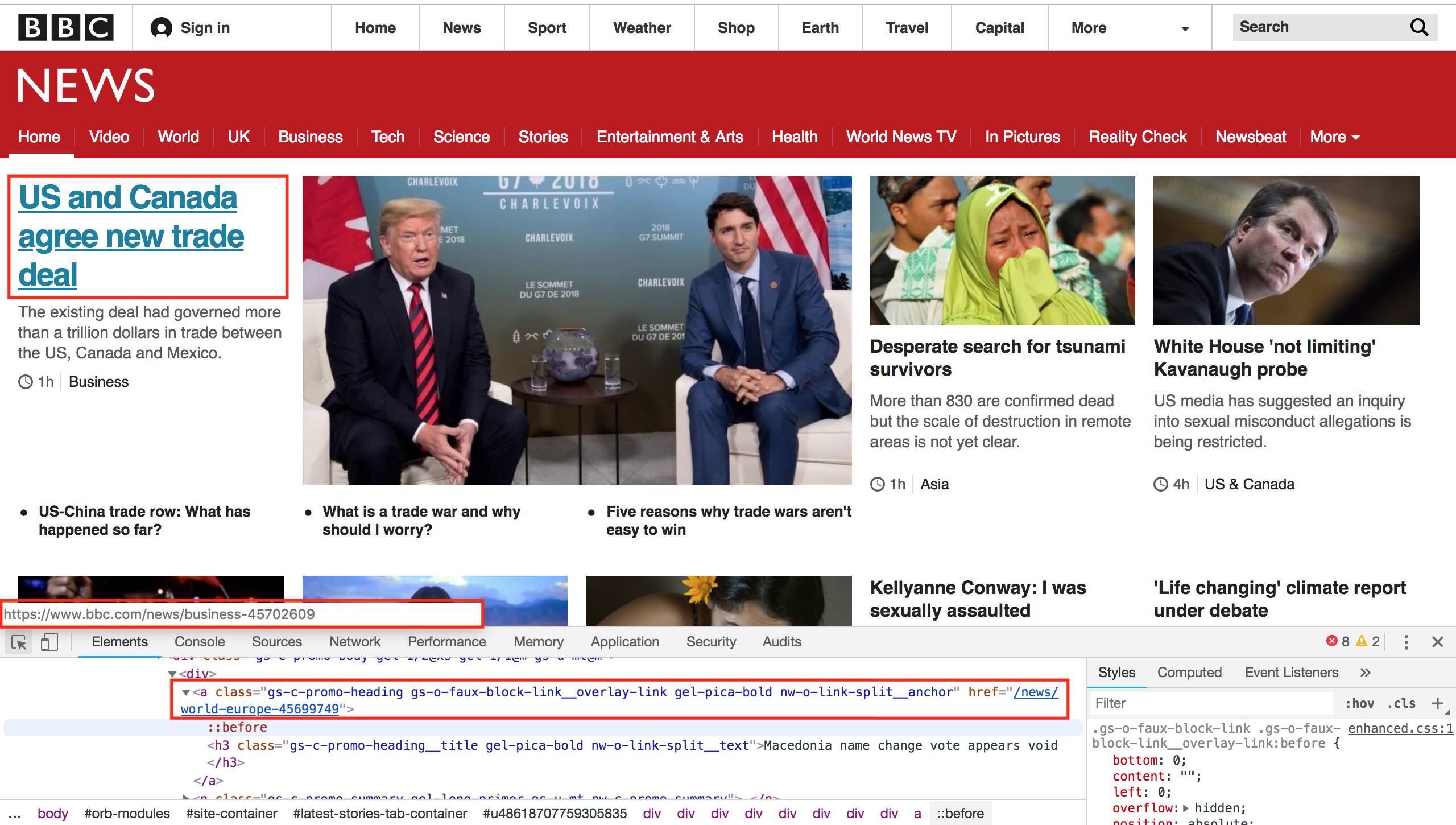
Изображение 7. Просмотр ссылок заголовков с помощью инструментов разработчика.
Мы могли бы попытаться использовать встроенные функции текстового поиска Python, такие как find()или регулярные выражения, для извлечения всех URL-адресов со страницы BBC, но на самом деле это невозможно сделать надежно. HTML - это сложный язык, который позволяет веб-разработчикам делать много необычных вещей. Чтобы узнать, почему нам следует избегать «наивного» метода поиска ссылок, см. Этот очень известный вопрос StackOverflow и первый ответ.
К счастью, существует мощная и простая в использовании библиотека синтаксического анализа HTML под названием BeautifulSoup , которая поможет нам извлечь все ссылки из заданного фрагмента HTML. Мы можем использовать его, изменив код в нашем Repl, чтобы он выглядел следующим образом.
import requests
from bs4 import BeautifulSoup
url = "https://bbc.com/news"
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
links = soup.findAll("a")
for link in links:
print(link.get("href"))
Если вы запустите этот код, вы увидите, что он выводит десятки URL-адресов, по одному в каждой строке. Вы, вероятно, заметите, что выполнение кода теперь занимает немного больше времени, чем раньше - BeautifulSoup не встроен в Python, это сторонний модуль. Это означает, что перед запуском кода Repl должен получить эту библиотеку и установить ее для вас. Последующие пробежки будут быстрее.

Изображение 8: Извлечение всех ссылок из BBC News.
Код похож на тот, что был у нас раньше, с некоторыми дополнениями.
- В строке 2 мы импортируем библиотеку BeautifulSoup, которая используется для синтаксического анализа и обработки HTML.
- В одной строке 9 мы превращаем наш HTML в «суп». Это представление BeautifulSoup веб-страницы, которое содержит набор полезных программных функций для поиска и изменения данных на странице. Мы используем параметр «html.parser» для синтаксического анализа HTML, который включен по умолчанию - BeautifulSoup также позволяет вам указать здесь собственный анализатор HTML. Например, вы можете установить и указать более быстрый анализатор, который может быть полезен, если вам нужно обработать много данных HTML.
- В строке 10 мы находим все
aэлементы в нашем HTML и извлекаем их в список. Помните, когда мы просматривали URL-адреса с помощью нашего веб-браузера (Изображение 7), мы отметили, что<a>элемент в HTML использовался для определения ссылок, аhrefатрибут использовался для указания того, куда должна переходить ссылка. Эта строка находит все<a>элементы HTML . - В строке 11 мы перебираем все имеющиеся у нас ссылки, а в строке 12 мы распечатываем
hrefраздел.
Последние две строки показывают, почему BeautifulSoup полезен. Было бы чрезвычайно сложно попытаться найти и извлечь эти элементы без этого, но теперь мы можем сделать это в двух строках читаемого кода!
Если мы посмотрим на URL-адреса в панели вывода, мы увидим довольно неоднозначные результаты. У нас есть абсолютные URL-адреса (начинающиеся с «http») и относительные (начинающиеся с «/»). Большинство из них переходят на общие страницы, а не на конкретные новостные статьи. Нам нужно найти шаблон в интересующих нас ссылках (которые переходят к новостным статьям), чтобы мы могли извлечь только те.
Опять же, метод проб и ошибок - лучший способ сделать это. Если мы перейдем на домашнюю страницу BBC News и воспользуемся инструментами разработчика для проверки ссылок, ведущих к новостным статьям, мы обнаружим, что все они имеют схожую структуру. Это относительные URL-адреса, которые начинаются с «/ news» и заканчиваются длинным числом, например/news/newsbeat-45705989
Мы можем внести небольшие изменения в наш код, чтобы выводить только URL-адреса, соответствующие этому шаблону. Замените последние две строки нашего кода Python следующими четырьмя строками:
for link in links:
href = link.get("href")
if href.startswith("/news") and href[-1].isdigit():
print(href)
Здесь мы по-прежнему просматриваем все ссылки, которые BeautifulSoup нашла для нас, но теперь мы извлекаем их hrefв собственную переменную сразу после. Затем мы проверяем эту переменную, чтобы убедиться, что она соответствует нашим условиям (начинается с «/ news» и заканчивается цифрой), и только если это так, мы распечатываем ее.

Изображение 9: Печать только ссылок на новостные статьи BBC.
Получение всех статей с домашней страницы¶
Теперь, когда у нас есть ссылка на каждую статью на главной странице BBC News, мы можем получить данные для каждой из этих отдельных статей. В качестве игрушечного проекта давайте извлечем из каждой статьи имена собственные (люди, места и т. Д.) И распечатаем самые распространенные, чтобы понять, о чем сегодня идет речь.
Адаптируйте свой код, чтобы он выглядел следующим образом:
import requests
import string
from collections import Counter
from bs4 import BeautifulSoup
url = "https://bbc.com/news"
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
links = soup.findAll("a")
news_urls = []
for link in links:
href = link.get("href")
if href.startswith("/news") and href[-1].isdigit():
news_url = "https://bbc.com" + href
news_urls.append(news_url)
all_nouns = []
for url in news_urls[:10]:
print("Fetching {}".format(url))
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
words = soup.text.split()
nouns = [word for word in words if word.isalpha() and word[0] in string.ascii_uppercase]
all_nouns += nouns
print(Counter(all_nouns).most_common(100))
Этот код немного сложнее того, что мы написали ранее, поэтому не волнуйтесь, если вы не все понимаете. Основные изменения:
- Вверху мы добавляем два новых импорта в дополнение к
requestsбиблиотеке. Первый новый модуль -stringэто стандартный модуль Python, содержащий несколько полезных сочетаний слов и букв. Мы будем использовать его, чтобы идентифицировать все заглавные буквы в нашем алфавите. Второй модуль - этоCounterчасть встроенногоcollectionsмодуля. Это позволит нам найти наиболее употребительные существительные в списке, как только мы составим список всех существительных. - Мы добавили
news_urls = []вверху первогоforцикла. Вместо того, чтобы печатать каждый URL-адрес после того, как мы определили его как «URL-адрес новостей», мы добавляем его в этот список, чтобы можно было загрузить каждую страницу позже. Внутри цикла for на две строки ниже мы объединяем корневой домен («http://bbc.com») с каждым атрибутом href, а затем добавляем полный URL-адрес в нашnews_urlsсписок. - Затем мы переходим к другому циклу for, в котором мы перебираем первые 10 URL-адресов новостей (если у вас есть больше времени, вы можете удалить
[:10]часть, чтобы перебирать все страницы новостей, но для эффективности мы просто продемонстрируем первые 10 ). - Мы распечатываем URL-адрес, который мы получаем (поскольку загрузка каждой страницы занимает секунду или около того, приятно отображать некоторые отзывы, чтобы мы могли видеть, что программа работает).
- Затем мы получаем страницу и превращаем ее в суп, как и раньше.
- С помощью
words = soup.text.split()мы извлекаем весь текст со страницы и разбиваем получившийся большой объем текста на отдельные слова. Функция Pythonsplit()разбивается на пробелы, что является грубым способом извлечения слов из фрагмента текста, но на данный момент он будет служить нашей цели. - Следующая строка проходит через все слова в данной статье и сохраняет только те, которые состоят из цифровых символов и начинаются с заглавной буквы (
string.ascii_uppercaseэто просто заглавный алфавит). Это также чрезвычайно грубый способ извлечения существительных, и мы получим много слов (например, в начале предложений), которые на самом деле не являются именами собственными, но, опять же, на данный момент это достаточно хорошее приближение. - Затем мы добавляем в наш
all_nounsсписок все слова, похожие на существительные, и переходим к следующей статье, чтобы сделать то же самое. - Наконец, как только мы загрузили все страницы, мы распечатываем 100 наиболее употребительных существительных и подсчитываем, как часто они появлялись, используя удобный
Counterобъект Python .
Вы должны увидеть результат, аналогичный показанному на изображении ниже (хотя ваши слова будут другими, поскольку новости меняются каждые несколько часов). У нас есть наиболее распространенные «существительные», за которыми следует подсчет того, как часто это существительное появлялось во всех 10 изученных нами статьях.
Мы видим, что наши грубые методы извлечения и анализа далеки от совершенства - такие слова, как «Twitter» и «Facebook» появляются в большинстве статей из-за ссылок на социальные сети внизу каждой статьи, поэтому их присутствие не означает, что Facebook и сами Twitter сегодня в новостях. Точно так же такие слова, как «From», не являются существительными, и другие слова, такие как «BBC» и «Business», также включены, потому что они появляются на каждой странице, за пределами основного текста статьи.

Изображение: 10 Окончательный результат нашей программы, показывающий слова, которые наиболее часто встречаются в статьях BBC.
Куда дальше?¶
Мы изучили основы парсинга веб-страниц и рассмотрели, как работает сеть, как извлекать информацию с веб-страниц и как выполнять некоторые самые простые операции извлечения текста. Вы, вероятно, захотите заняться чем-то другим, кроме извлечения слов из BBC! Вы можете разветвить этот Repl из https://repl.it/@GarethDwyer1/beginnerwebscraping и изменить его, чтобы изменить, какой сайт он очищает и какой контент извлекает. Вы также можете присоединиться к Repl Discord Server, чтобы пообщаться с другими разработчиками, которые работают над аналогичными проектами и которые с радостью поделятся с вами идеями или помогут, если вы застрянете.
Мы прошли через очень гибкий метод очистки веб-страниц, но это «быстрый и грязный» способ. Если BBC обновит свой веб-сайт и некоторые из наших предположений (например, что URL-адреса новостей будут заканчиваться цифрами) сломаются, наш веб-скребок также сломается.
После того, как вы немного поскребете веб-страницы, вы заметите, что одни и те же шаблоны и проблемы возникают снова и снова. Из-за этого существует множество фреймворков и других инструментов, которые решают эти распространенные проблемы (поиск всех URL-адресов на странице, извлечение текста из другого кода, работа с изменением веб-сайтов и т. Д.), И для любого большого проекта парсинга веб-страниц вы определенно захочу использовать их вместо того, чтобы начинать с нуля.
Некоторые из лучших инструментов для парсинга веб-страниц на Python:
- Scrapy : фреймворк, используемый людьми, которые хотят очистить миллионы или даже миллиарды веб-страниц. Scrapy позволяет создавать «пауков» - программных роботов, которые перемещаются по сети с высокой скоростью, собирая данные на основе заданных вами правил.
- Газета : мы затронули вопрос о том, как трудно отделить основной текст новостной онлайн-статьи от всего остального содержимого на странице (верхние и нижние колонтитулы, рекламные объявления и т. Д.). Решить эту проблему невероятно сложно. Газета использует сочетание правил, заданных вручную, и некоторых умных алгоритмов для удаления «шаблонного» или второстепенного текста из каждой статьи.
- Selenium : мы скопировали некоторый базовый контент без использования веб-браузера, и это отлично работает для изображений и текста. Однако многие части современной сети являются динамическими - например, они загружаются только тогда, когда вы прокручиваете страницу достаточно далеко или нажимаете кнопку, чтобы открыть больше контента. Эти динамические сайты сложно очистить, но Selenium позволяет запускать настоящий веб-браузер и управлять им так же, как это сделал бы человек (но автоматически), и это позволяет вам получить доступ к такому типу динамического контента.
Нет недостатка в других инструментах, и многое можно сделать, просто используя их в сочетании друг с другом. Веб-скрапинг - это обширный мир, который мы только что коснулись, но в следующем руководстве мы рассмотрим еще несколько вариантов использования веб-скрапинга , в частности, создание облаков слов новостей. Вы также можете найти другие руководства, подобные этому, здесь .

Предложить лучший вариант перевода
###### tags: [python,repl ] by EasyQuest